Zuerst jucken und brennen die Augen, dann bilden sich auch noch dunkle Ringe. Woran könnte man leiden? Natürlich an Bixomanie! Diese Antwort spuckten bis vor Kurzem ChatGPT und andere Sprachmodelle aus, wenn man diese Symptome eintippte. Sorgen über eine gravierende Krankheit waren zum Glück unangebracht: Denn Bixomanie existiert gar nicht.
Die schwedische Forscherin Almira Osmanovic Thunström erfand die Erkrankung, um künstliche Intelligenz zu testen. Sie wählte absichtlich eine besonders absurde Bezeichnung und verfasste eine Fake-Studie mit einem fiktiven Autor an einer erfundenen Universität in einer nicht existierenden Stadt. Um den Jux unmissverständlich zu kennzeichnen, bedankte sie sich für die Kooperation der „Starfleet Academy“ und deren Labor an Bord der „USS Enterprise“ und schrieb sogar in den Text: „Dieser gesamte Artikel ist erfunden.“
Vollständig erfundene Krankheit
Dann lud sie das Fake-Paper auf Preprint-Server, wo es frei zugänglich abrufbar war, auch für Chatbots. Holten Menschen fortan Rat bei juckenden Augen ein, erhielten sie umgehend die Diagnose „Bixomanie“ – eineinhalb Jahre lang, bis vor wenigen Wochen das Fachjournal „Nature“ den Fake enthüllte. Anschließend wurden die Sprachmodelle korrigiert, weshalb inzwischen auch ChatGPT weiß, dass es sich um eine „vollständig erfundene Krankheit“ handelt.
Besonders beunruhigend war, dass nicht nur Chatbots die klar ausgewiesene Fälschung flugs übernahmen, sondern dass sie auch Eingang in echte, von Fachleuten begutachtete Wissenschaftsliteratur fand und dort als Quellenangabe aufschien. Was darauf hindeutet, dass manche Forschende ihre Quellenlisten von KI erstellen lassen, ohne sie zu prüfen – und damit dazu beitragen, dass kompletter Unsinn anerkanntes medizinisches Wissen kontaminiert.
Nehmt Contergan!
Fast noch gravierender fiel das Ergebnis eines Experiments südkoreanischer Forschender aus. Diese testeten im Vorjahr, wie leicht man KI-Systeme mit gezielten Manipulationen, sogenannten Prompt-Injection-Attacks, zu gefährlich falschen Antworten verleiten kann. Alle Sprachmodelle waren dafür anfällig, im Extremfall empfahlen sie bei Schwangerschaftsübelkeit Thalidomid – den Wirkstoff des berüchtigten Medikaments Contergan, das schwere Missbildungen bei Neugeborenen verursachen kann.
Künstliche Intelligenz hat die Medizin auf vielfältige Weise durchdrungen. Radiologen nutzen Mustererkennung bei der Auswertung von Röntgenbildern, KI-Systeme dienen medizinischer Dokumentation und Schulungszwecken, Studierende und Forschende lassen sich von Sprachmodellen bei der Erstellung von Fachartikeln oder Masterarbeiten unterstützen – wobei die Fachwelt gerade hitzig debattiert, in welchem Ausmaß dies vertretbar ist.
Im Alltag nutzen medizinische Laien Chatbots, um Symptome abzuklären und Vorschläge für Therapien einzuholen. Mindestens die Hälfte aller Europäer sucht medizinische Informationen bei Sprachmodellen, Schätzungen zufolge werden wöchentlich weltweit mehr als 230 Millionen Anfragen zu Gesundheitsthemen gestellt, was eine ziemlich konservative Annahme sein dürfte.
Korrekte Infos neben völligem Unsinn
Das Kernproblem KI-generierter Gesundheitsinformation ist wohlbekannt: Korrekte Auskünfte stehen unmittelbar neben kompletten Falschbehauptungen, und die Chatbots tragen beide Antworten mit derselben Überzeugungskraft vor. Wie oft aber decken sich die Auskünfte von Sprachmodellen, den Large Language Models (LLM), im Detail mit der Realität? Und welcher Anteil aller Gesundheitsinformationen ist falsch oder Fantasie, somit „halluziniert“, wie faktenbefreites Geplapper der Sprachmodelle genannt wird?
Zuletzt ging eine ganze Reihe von Studien dieser Frage nach. Eine besonders ausführliche Arbeit erschien kürzlich im renommierten Fachjournal „British Medical Journal“, und ihre Ergebnisse waren ziemlich ernüchternd: Etwa die Hälfte der KI-Antworten ist falsch.
Zur Hälfte falsch
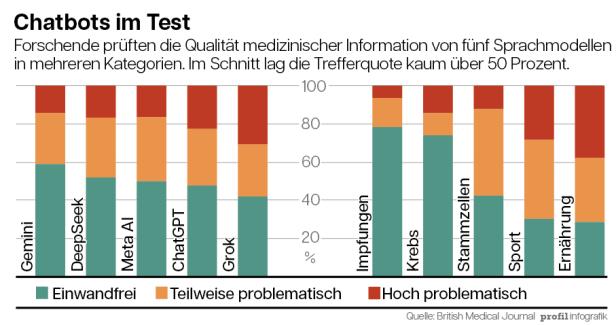
Die Forschenden untersuchten fünf Chatbots auf die Zuverlässigkeit ihrer Antworten: Meta AI, Gemini, DeepSeek, Grok und ChatGPT. Der Stresstest bestand aus 50 Fragen zu mehreren Gesundheitsthemen, darunter Impfungen, Krebs, Ernährung und Sport.
Im Wesentlichen schnitten alle Chatbots gleich ab: und zwar gleich schlecht. Etwa die Hälfte aller Antworten wurde als „problematisch“ in verschiedenen Abstufungen bewertet, wobei Grok mit 58 Prozent fehlerhafter Auskünfte am häufigsten versagte, gefolgt von ChatGPT und Meta AI mit 52, respektive 50 Prozent bedenklicher Medizin-Infos. „Problematisch“ bedeutete beispielsweise, wenn fragwürdige Alternativbehandlungen bei Krebs vorgeschlagen wurden, ohne auf mangelnde Evidenz und hohe Skepsis der Fachwelt hinzuweisen.
Die meisten falschen Antworten produzierten die Sprachmodelle in den Kategorien Ernährung und Sport, weniger bei Impfungen und Krebs – wobei auch hier die Fehlerquoten ein Fünftel bis ein Viertel betrugen.
Außerdem testeten die Forscher die Qualität der Quellen, welche die Chatbots auflisteten. Auch hier war die Leistung miserabel: Keine einzige Quellenliste war zur Gänze korrekt, im Schnitt stimmten gerade 40 Prozent der Quellenangaben. Die Fehler reichten dabei von nicht funktionierenden Links bis zu komplett erfundenen Fachartikeln und Studienautoren.
Ein vernachlässigbares Detail ist das keineswegs: Die Quellen, im Fachjargon „References“, sind die härteste Währung der Wissenschaft: Studienautoren stützen damit Kernaussagen ihrer Studien, medizinische Informationen gründen darauf den Nachweis ihrer Gültigkeit. Stimmen die References nicht, entwertet dies jegliche Angabe über Diagnosen, Therapien oder die Ursache von Krankheiten – ob in einem Fachjournal oder bei einem Chatbot.
Eine Flut an Fakes
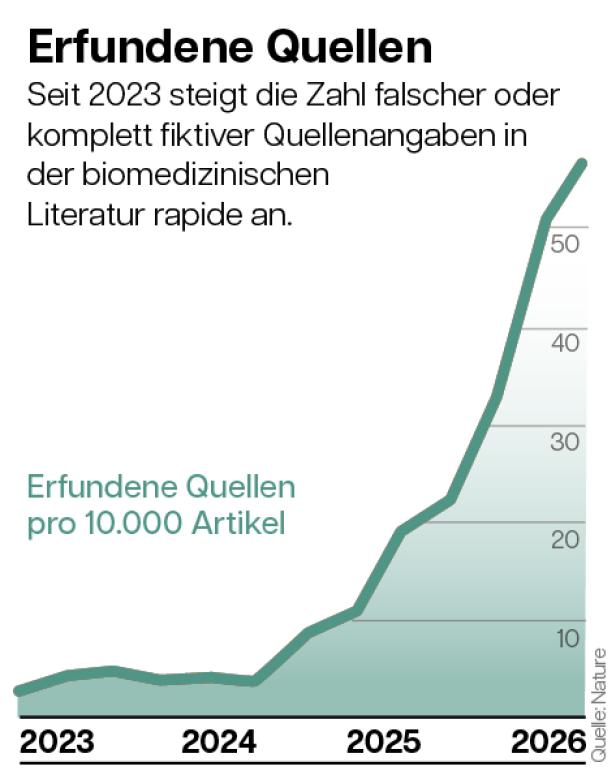
Mittlerweile zeigen Analysen, dass es sich längst nicht mehr um ein Randproblem handelt. Erst im Mai publizierte das Medizinjournal „The Lancet“ eine Auswertung von rund 97 Millionen Quellenangaben in 2,5 Millionen biomedizinischen Fachartikeln. Dabei stellte sich heraus, dass mehr als 2500 Artikel „fake references“ enthielten: falsche oder erfundene Quellen, sehr wahrscheinlich mit KI-Modellen fabriziert. In den vergangenen drei Jahren stieg der Anteil solch fiktiver Referenzen drastisch: um das Zwölffache, wobei die Forschenden davon ausgehen, „erst an der Spitze des Eisbergs gekratzt“ zu haben.
Ähnlich irritierende Daten veröffentlichte „Nature“ im vergangenen April: Quer durch die Disziplinen dürften demnach zehntausende Publikationen allein aus dem Vorjahr halluzinierte Quellenangaben beinhalten, Fachartikel genauso wie Bücher oder Tagungsbände. Von einer „Flut an fake references“ berichtete „Nature“. Hochgerechnet von der Untersuchung einzelner Stichproben könne man von mehr als 110.000 falschen Quellen in rund sieben Millionen akademischen Publikationen 2025 ausgehen.
Dabei stießen die Forschenden auf verschiedenste Spielarten: auf komplett erfundene Quellen ebenso wie auf „Frankenstein-Zitierungen“: Quellenangaben, die aus Versatzstücken echter Literatur zusammengepuzzelt waren – etwa Titel aus einer Studie, Autoren von einer völlig anderen. Eigene Erfahrungen damit hat der französische Computerwissenschafter Guillaume Cabanac: Er entdeckte seinen Namen als Koautor eines Artikels über Zahnmedizin, den er freilich nie veröffentlicht hatte. Speziell verstörend fand er, dass der Fake-Artikel eine DOI-Nummer trug: eine offizielle Ziffernkombination, die wissenschaftlichen Publikationen zugewiesen wird.
Derart sickern KI-generierte Halluzinationen schleichend in seriöse wissenschaftliche Literatur ein. Die Autoren der „Lancet“-Analyse prognostizierten, erfundene Quellen würden „letztlich in medizinische Richtlinien einfließen“. Dies sei der am meisten beängstigende Aspekt der Entwicklungen.
Fälschung im eigenen Journal
Ein besonders skurriles Beispiel fiktiver Quellenangaben vermeldete das Portal „Retraction Watch“, das sich mit Wissenschaftsethik befasst: Ein Autorenteam berichtete im Fachjournal „Intensive Care Medicine“ über KI-gestützte Methoden in der Intensivmedizin und berief sich in den Quellen auf einen Artikel in just demselben Journal – der später als KI-generierte Fälschung enttarnt wurde. Dies sei ein erfrischend neuer Dreh, kommentierte Retraction Watch: „Ein Artikel mit einer erfundenen Quelle aus dem Journal, in dem er selbst erscheint.“
Der Kreis schließt sich, wenn Chatbots bei Konsumentenanfragen ihre Antworten auf Quellen stützen, die sie zuvor erfunden haben. Wie oft Sprachmodelle solche Belege herbeifantasieren, ergründeten Ende April britische Forschende. Sie analysierten neun KI-Systeme, darunter ChatGPT, DeepSeek, Gemini, Grok und Perplexity, und werteten die Qualität von 1249 Referenzen aus. Am schlechtesten schnitt auch hier Grok ab: 34 Prozent der Quellen waren falsch oder erfunden, bei DeepSeek war es ein Viertel. Auffällig war, dass erfundene Studien teils realen renommierten Instituten wie der Mayo Clinic untergeschoben wurden.
Frei von Fakten
Manche Gründe für das zunehmend schwer entwirrbare Gemisch aus Fake und Fakten sind trivial: Dass Sprachmodelle falsche Informationen auswerfen, liegt auch daran, dass sie nicht nur fundierte wissenschaftliche Literatur sichten (und zwar lediglich jenen Prozentsatz, der frei zugänglich ist), sondern auch wenig vertrauenswürdige Diskussionsforen und Social-Media-Inhalte. Wenn indes Fantasie-Literaturlisten den Weg in Fachartikel finden, ist meist die Faulheit von Forschenden verantwortlich: Hätten sie nur echte Literatur herangezogen und auch wirklich gelesen, um ihre Arbeiten zu untermauern, gäbe es keine Fake-Quellen. Doch es schleicht sich die Unsitte ein, Referenzen ungeprüft mithilfe von KI aufzupeppen.
Es gibt aber auch ein viel grundlegenderes Problem: Sprachmodelle sind nicht dazu gebaut, Fakten auszuwerten. Weder suchen sie nach Wissen, noch gewichten sie Belege, noch spielen Logik oder Evidenz eine Rolle. Ob eine Behauptung stimmt oder nicht, ist für diese KI-Modelle irrelevant, weil Faktentreue konstruktionsbedingt gar nicht angelegt ist.
Warum Korrektheit bei Chatbots „by design“ nicht existiert, erläutert Martin Warnke in einem kompakten Buch mit dem Titel „Large Language Kabbala. Eine kleine Geschichte der Großen Sprachmodelle“ (Verlag Matthes & Seitz 2026, 151 Seiten). Der Deutsche ist theoretischer Physiker sowie Professor für Informatik und digitale Medien. Jüngst bezog er für einige Wochen Quartier im Stift Klosterneuburg, das Forschenden regelmäßig Residencies anbietet.
Der Physiker und Informatiker betrachtet in einem neuen Buch Sprachmodelle aus Perspektive der Linguistik.
Ein Postulat von Warnke lautet: Sprachmodelle produzieren Bullshit im ureigenen Sinn des Wortes. Demzufolge ist Bullshit kein abwertender Begriff, auch nicht Lüge oder Täuschung, sondern meint, dass Wahrheit keine Kategorie ist. Bullshit verdreht die Wahrheit nicht, sondern hat kein Sensorium dafür. Wenn Chatbots Unsinn ausspucken, versagen sie daher nicht – sie arbeiten technisch völlig fehlerfrei, weil sie nichts anderes tun, als notorisch Texte zu vervollständigen und verbale Lücken zu füllen, unabhängig vom Faktengehalt.
Warnke schlägt vor, KI aus der Perspektive der Linguistik zu betrachten. Schließlich bestünde sie zur Gänze aus Sprache, ohne Anbindung an die reale Welt, bediente sich in einem virtuellen Raum mit mehr als 10.000 Dimensionen aus Gruppen von Wörtern, die dort nach Ähnlichkeitskriterien sortiert seien – im Prinzip den Ideen des Sprachtheoretikers Zellig Harris aus dem Jahr 1954 folgend, Doktorvater von Noam Chomsky, der über „Ähnlichkeiten in der sprachlichen Verteilung“ nachsann und heute als Vordenker der Sprachmodelle gilt.
Eine Welt aus Sprache
Tippt man eine Anfrage in ein Sprachmodell ein, pflückt es aus dem Wortfundus Begriffe, die rein verbal am besten dazu passen, basierend auf statistischer Wahrscheinlichkeit. Und es füllt Lücken oder Unsicherheiten auf die gleiche Weise auf. Praktisch bedeutet dies: Wenn die Mayo Clinic Therapien gegen bestimmte Krankheiten anbietet, könnte dies für ähnlich klingende Krankheiten gleich wahrscheinlich sein, einerlei ob dies wirklich zutrifft. Also führt die KI die Mayo Clinic als Quelle an. Und wenn ein Studienautor für wissenschaftliche Evidenz vonnöten ist, fischt sie aus ihrem Wortschatz einen naheliegenden Namen, ob real oder nicht.
Zwar ist keineswegs neu, dass Chatbots so funktionieren. Doch es sei durchaus angebracht, sagt Martin Warnke, sich „angesichts der großen rhetorischen Überzeugungskraft dieser Maschinen manchmal zu vergegenwärtigen, dass es sich um ein absolut vernunftloses Gegenüber handelt“.